Successful AI/ML solutions are built on solid data foundations
Data processing lives at the heart of successful Machine Learning strategy. ML models are built from data inputs therfore the quality and availability of data directly informs the model accuracy, efficiency and application to the underlying business processes.
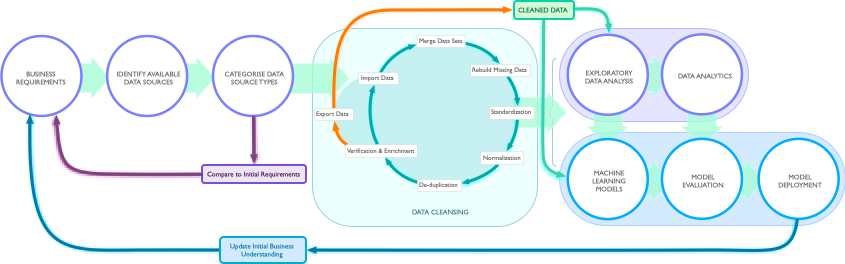
What Data Sources are available in the current business context. What are the data types provided by the available sources.
Data quality considerations, is the available data structured or unstructured. What is the estimated effort required to make the data usable for Machine Learning algorithms.
When multiple data sources are available, compare and contrast quality, data type and effort required to ingest data.
Streaming vs batching and data caching considerations. Can/should data be consumed directly from source systems continously in real-time or is batch processing of data an acceptable option.
All the considerations above inform the overall architecture of the Machine Learning process.
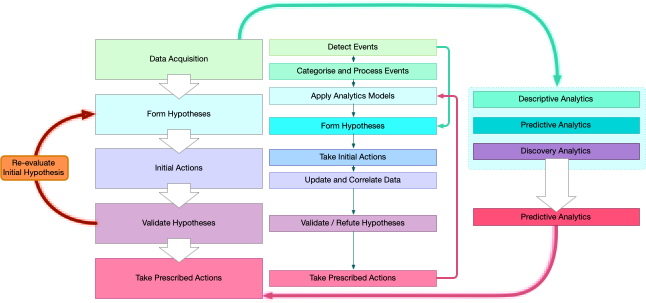
Representation of a general data analytics model. The model is iterative through a cycle of building hypotheses from available data, validating these hypotheses and taking informed actions. The initial hypothesis is continually refined, both through the results of the actions undertaken, and continuous inputs of new data.